

Implizites Wissen
Bestimmte Informationen werden im Web nicht explizit dargestellt und werden erst aus der Kombination von gegebenen Daten gebildet. Durch die Kombinatorik können Ableitungen und Schlussfolgerungen gebildet werden und dadurch kommen formal logische Methoden zum Einsatz, um automatisch Schlussfolgern zu können.
Es gibt zwei Wege um Web-Informationen auszuwerten:
Ad hoc
Fokusiert was offensichtlich erkennt wird und drauf werden Regelsysteme eingesetzt, um logische Ableitungen zu folgern.
Dadurch können auch noch mehr Informationen von der gleichen Internetquelle gewonnen werden die nicht sofort eindeutig sichtbar sind.
A priori
Beschreibt explizite Information. Der Zustand wird erreicht wenn Web-Anbieter von sich aus zusätzliche Informationen preisgeben, die dann beschreiben welche Information grade dargestellt werden. Daraus folgt der Semantic Web Ansatz
Voraussetzungen
Semantic Web bietet offene Standards zur Beschreibung von Informationen. Diese Standards sind klar definiert, flexibel und erweiterbar. Zusätzlich gibt es logische Beschreibungslogiken, die auf die Beschreibungssprachen zugreifen können und Dinge verifizieren oder bestimmte logische Schlüsse ziehen.
Für das Semantic Web sind viele Komponenten notwendig die in einer einheitlichen Logik miteinander verbunden sind.
Die Kernkomponenten vom Semantic Web werden in der untern Grafik gelb-rot dargestellt.

Die Trust -Komponente kümmert sich um die Beweisbarkeit von Informationen. Z.B. welcher Information wird im Web vertraut wird und kann diese Information auch sichergestellt bzw. verifiziert werden.
XML
Steht für eXtensible Markup Language um Inhalte bzw. Datenstrukturen im Web zu beschreiben.
Innerhalb der Datenbanksichtweise wird XML für semi-strukturierte Daten verwendet. Durch die Mehrdeutigkeit ist XML nicht optimal für die Beschreibung von Metadaten. In dem unteren Beispiel ist die Information nicht eindeutig. Es kann entweder der Verleger im Vordergrund stehen, das Buch oder beides gleichwertig sein. Der Zustand das alles gleich ist verursacht aber Probleme bei einer automatischen Interpretation der gegebenen Information. XML baut dadurch eine Baum Architektur.

URIs
Uniform Ressource Identifier. Die Idee ist das allem was im Web dargestellt wird eine eindeutige ID zu vergeben.
Diese Komponente macht sich das Semantic Web insbesondere zu nutze, um zu definieren, um welche Informationen es sich genau handelt.
RDF - Ressource Description Framework
Dieses Framework wird verwendet um Metadaten zu erfassen. RDF ist eine Sprache mit der es ermöglicht wird Metainformationen auszulesen. Das Framework baut Sätze mit Subjekt, Prädikat und Objekt. Nach diesen Prinzipien ist die RDF Sprache entstanden.
RDF ist eine Ansammlung von Tripeln wo ein Subjekt, Prädikat und Objekt existieren. Die gesamte Sprache ist beim W3C standardisiert.
Es wird ein gerichteter Graph gebildet und keine Baumstruktur erstellt wie bei XML.

RDF - Bestandteile
URIs dienen zur eindeutigen Referenzierung von Resourcen. Literale bescheiben die Datenwerte, die wiederum keine eigene Identität verwenden. Zusätzlich wurden leere Knoten eingeführt, die bestimmte Existenzaussagen über ein Individuum erlauben.
RDF - Literale
Literale werden als Zeichenketten dargestellt. Es kann auch ein Datentyp zugewiesen werden. Es wird dabei auf XML Schemes zurückgegriffen wo Datentypen bereits vordefiniert sind. Wenn kein Datentyp explizit angeben wird liest der Interpreter an dieser Stelle immer eine Zeichenkette.

RDF - Tripel
Es existieren unterschiedliche Darstellungsmöglichkeiten, so dass eine Liste von (Knoten-Kante-Knoten) Tripeln ermöglicht wird. Alles kann eine URI sein und weiter beschrieben werden. Das Subjekt und das Objekt können leere Knoten sein.

RDF - Leerer Knoten
Diese Knoten dienen als Hilfsknoten für Ressourcen die optional unbenannt bleiben. Durch diese Graphenanordnung werden Existenzaussagen ermöglicht.

RDF - Syntax
Es gibt vier verschiedene Syntax Möglichkeiten in RDF.
1. XML Dialekt
Es werden Namespaces eingesetzt, um die Eindeutigkeit von RDF Tagbezeichnungen zu unterstreichen. Der Verweis richtet sich dann an die W3.org und die RDF Syntax und zusätzlich wird ein eigenständiger Namespace benötigt um die Prädikate zu definieren.
In dem unteren Beispiel wird über das RDF-Description Tag, Subjekte und Objekte referenziert. Hinter dem About Attribute erscheint die URI des Subjekts, um das es dann geht. Innendrin steht das Prädikat.

2. N3 Diese Notation ist relativ umfangreich und erlaubt die Nutzung von Formeln und Regeln.
3. N-Triples (Ist eine Untermenge von der N3 Notation )
4. Turtle
Eine Erweiterung von N-Triples. Die URIs werden in spitzen Klammern dargestellt. Die Literale werden in Anführungszeichen dargestellt und die Tripel werden durch deinen Punkt abgeschlossen. Die Leerzeichen und Zeilenumbrüche außerhalb von Bezeichnern werden ignoriert. Innerhalb der Turtle Syntax wird das Subjekt, Prädikat und Objekt direkt gebaut und nicht geschachtelt über einen XML Baum.
Turtle ist deutlich intuitiver als XML und lässt sich direkt ablesen. Leider existieren derzeit bessere und vor allem mehrere Programmbibliotheken für XML als für Turtle.

Beispiel mit der Verwendung eines Prefix um die Syntax deutlich zu entschlacken und zu verkürzen.

RDFS - Schemawissen
Angestrebt wird, dass viele logische Zusammenhänge zwischen Individuen, Klassen und Beziehungen beim Entstehungsprozess bereits eingefangen werden mit den Ziel möglichst viel Semantik des Gegenstandbereiches einzufangen. Dadurch können dann Aussagen formuliert werden wie z.B: das Verlage Organisationen sind und Bücher werden nur von Personen geschrieben. Es soll eine Art Bedeutungsmetastruktur definiert werden. Dabei wird über der RDF Ebene eine zusätzliche RDFS Ebene oberhalb definiert.
Bei RDFS wird ein spezielles RDF Vokabular zugrunde gelegt und hat einen eigenen Namensraum(rdfs).
Dadurch werden Spezifikation von schematischen und terminologischem Wissen ermöglicht. Zusätzlich können jetzt Klassen und Instanzen definiert werden.
RDFS - Klassen und Instanzen
Beispiel: ex:SemanticWeb rdf:type ex:Lehrbuch .
Dieses sagt semantische aus das, dass Semanticwebbuch von der Klasse Lehrbuch ist. Es können dabei belibig viele Tripel gleichzeitig erzeugt werden denn die Klassenzugehörigkeit ist nicht exlusiv. So wäre die zusätzliche Definition:
ex:SemanticWeb rdf:type ex:KurzesKompaktesBuch . auch möglich. Es findet syntaktisch keine Unterscheidung zwischen Klassen und Instanzen statt, dieses Verhalten ist auch bewusst gewollt. ex:SemanticWeb ist in diesen konkreten Fall eine Instanz könnte aber genau so gut eine Klasse sein, indem ein Buchkapitel aus einem anderen Buch beschrieben wird. Diese Entscheidung wird absichtlich offen gelassen, um möglichst viele Entscheidungen treffen zu können.
Soll ein Bestandteil explizit als eine Klasse deklariert werden kann die Typisierung über rdfs:Class verwendet werden.
Z.B: ex:Lehrbuch rdf:type rdfs:Class . Wenn die Metaebene ausgedrückt werden soll kann natürlich festgelegt werden das rdfs:Class selber eine eigenständige Klasse ist wie im folgenden Beispiel: rdfs:Class rdf:type rdfs:Class .
RDFS - Sub-Klassen
Die Problematik gegenüber der Programmierung wo sich alles innerhalb eines Sourcecodes befindet ist, dass die benötigten Tripel frei im Internet verteilt sind. Dadurch kann es keine eindeutigen taxonomien geben, weil es keine Sub-Klassenbezeihung gibt. Das bedeutet wenn ein vorhandenes Tripel mit der Klasse Lehrbuch deklariert wird: ex:SemanticWeb rdf:type ex:Lehrbuch . und die Suche nach der Klasse Buch ausgeführt wird: ex:Buch . Wird diese Suche keine Resultate liefern, weil kein Zusammenhang zwischen Lehrbuch und Buch hergestellt ist. Das Problem kann einerseits durch das Hinzufügen von zusätzlichen Tripeln behoben werden.
ex:SemanticWeb rdf:type ex:Buch . aber durch diese Herangehensweise wäre nur das Problem für die Instanz SemanticWeb gelöst und nicht für andere Bücher. Deswegen kann durch eine zusätzliche rdfs:subClassOf Property einmal die konkrete Subklasse definiert werden: ex:Lehrbuch rdfs:subClassOf ex:Buch . Ab diesen Definitionszeitpunkt ist jede Instanz der Klasse: ex:Lehrbuch automatisch eine Instanz der Klasse´: ex:Buch. Diese Property ist Reflexiv, dass bedeutet jede Klasse ist eine Unterklasse von sich selbst. Durch die Reflexivität wird die Klassenäquivalenz hergestellt, indem beide definierten Klassen, wiederum Sub-Klassen voneinander sind wie im folgenden Beispiel:
ex:Hospital rdfs:subClassOf ex:Krankenhaus .
ex:Krankenhaus rdfs:subClassOf ex:Hospital .
RDFS - Klassenhierarchien
Durch Klassenhierachien werden Taxonomien wiederum ermöglicht.
ex:Lehrbuch rdfs:subClassOf ex:Buch .
ex:Buch rdfs:subClassOf ex:Printmedium .
ex:Zeitschrift rdfs:subClassOf ex:Printmedium .
Dabei gillt die mathematische Transitivität durch die rdfs:subClassOf Property.
Somit gilt automatisch das ein Lehrbuch auch ein Sub-Klasse des Printmedium ist
RDFS - Shorthand
Die Darstellung der Klasseninstanz kann verkürzt dargestellt werden.
<rdf:Description rdf:about=
"&ex;SebastianRudolph">
<rdf:type rdf:resource= "&ex;HomoSapiens"/>
</rdf:Description>
Durch die Verkürzung indem vorne die Klassen vorangestellt und hinten wird der Verweis auf die Instanz beschrieben:
<ex:HomoSapiens rdf:about="&ex;SebastianRudolph"/>
Es gibt noch weitere Shorthand-Schreibweisen innerhalb des XML Stacks die eingeführt worden sind, um an dieser Stelle deutlich viel Schreibarbeit zu sparen.
RDFS - Properties
Mit Properties werden die Beziehungen bzw. Relationen die zwischen Instanzen der Klasse bestehen definiert. Im Gegensatz zur OOP werden Porperties nicht speziellen Klassen zugeordnet sonder diese existieren frei im Raum.
ex:verlegtBei rdf:type rdf:Property .
In diesen Beispiel kann die Porperty verlegtBei alles mögliche sein und muss im weiteren Verlauf noch von dem entsprechenden Author mit Sinn und Einschränkungen gefüllt werden. Properties - Bezeichner sind erneut Tripel.
Es geht darum Prädikate zu definieren. Das bedeutet die Prädikate charakterisieren den Zusammenhang und mathematisch kann dieser Zusammenhang als eine Menge von Paaren dargestellt werden.
RDFS - Sub-Properties
Hier leigt die Analogie wie bei den Sub-Klassen. Die Sub-Propertie wird durch rdfs:subPropertyOf gekennzeichnet.
Alle gleichen Regeln gelten erneut also auch die Transitivität.
ex:glücklichVerheiratetMit rdf:subPropertyOf rdf:verheiratetMit .
ex:Homer ex:glücklichVerheiratetMit ex:Marge .
Schlussfolgerung: ex:Homer ex:verheiratetMit ex:Marge .
RDFS - Properties Einschränkungen
Es ist nur für bestimmte Instanzen sinnvoll mit einem Prädikat beschrieben zu werden. Daher können Properties über Domains und Ranges eingeschränkt werden. Die Keywords lauten: rdfs:domain (Definitionsbereich) und rdfs:range (Wertebereich).
ex:verlegtBei rdfs:domain ex:Publikation .
ex:verlegtBei rdfs:range ex:Verlag .
Diese Eintschränkung kann auch auf Literale angwendet werden:
ex:hatAlter rdfs:range xsd:nonNegativeInteger .
Wenn diese Einschränkung erfolgt ist wirkt sie global und konjunktiv. Es ist die einzige Möglichkeit in
rdf eine semantische Beziehung zwischen Properties und Klassen herzustellen.

SPARQL ist die Anfragesprache zur Abfrage aus RDF Instanzen.
Es spezifiziert die Anfragesprache selbst. Das Ergebnis wird in XML zurückgeliefert. Es werden dabei konkrete Anfragemuster definiert. Es ähnelt ein wenig SQL. Innerhalb der SELECT-Klausel wird definiert was der Bestandteil des Ergebnisses sein soll. Durch das PREFIX wird auch hier die Möglichkeit von Shorthand-Schreibweisen ermöglicht. Das WHERE ist der Hauptbestandteil dieser Musteranfrage und verwendet in seinem Definitionsbereich die Turtle-Syntax. Dort werden konkrete RDF-Tripel angefragt, die diesen Muster entsprechen.
Es existieren Variablen, die mit einen ?Fragezeichen deklariert werden. Diese Variablen können mehrfach verwendet werden.
Diese Anfrage bewirkt das im gesamte RDF Graphen nach diesen Muster RDF Tripel gesucht wird.

Die obere Anfrage durchsucht dieses gegeben Beispieldokument:

und liefert als Ergebnis für jedes gefundene Tripel eine eigenständige Zeile.

SPARQL Graphmuster und Filter
Die Turtleabkürzungen, die in RDF existieren sind auch in SPARQL zulässig. Für Variablen können ? oder $ verwendet werden.
Die Variablen können alles semantisch logische sein. Bedeutet entweder Subjekt, Prädikat oder Objekt. Bei SPARQL können Datentypen explizit berücksichtigt werden. Bedeutet des Resultat kann ein Tripel sein oder auch Teile von Tripeln zurückliefern. Es können auch direkte Typen Abfrage definiert werden wie gib jedes Objekt zurück das den Datentyp Integer verwendet. Optionale Muster: wie Kann zutreffen muss aber nicht zutreffen sind möglich. Alternativemuster wie: kann etwa so oder so sein und es kann auch nach bestimmten Werten gefiltert werden. Viele Filterfunktionen kommen ursprünglich aus der XML Welt.
Hier ist ein konkretes Filterbeispiel wo jedes Buch angezeigt wird, dass weniger als 35 € kostet.

Durch die Select * ist auch wie in SQL die Selektierung von Allem möglich. Der Nachteil ist das sich innerhalb des Ergebnisses Redundanzen bilden und das die Beziehung der Objekte nicht mehr offensichtlich ist.
Das Ausgabeformat kann aber noch weiterformatiert werden. Die Situation ist dann interessant wenn mit den Ausgabeformat noch weitergearbeitet werden soll. Hier kommt das CONSTRUCT ins Spiel. Dadurch wird der Turtle-Sytanx Support ermöglicht und es kann eine Ausgabeschablone definiert werden für ein spezielles Ausgabeformat.
Ontologie
Innerhalb des Semantic Web Stacks steckt immer eine Ontologie dahinter und beschreiben z.B. in der Philosophie die Lehre vom Sein. Dabei existiert immer nur eine Ontologie und nicht mehrere Ontologien. Viele zahlreiche bekannte Philosophen von Kant bis Sokrates haben sich mit der Ontologie befasst. Mit Kernfragen wie:
Wie verstehen wir das Sein. Wie verstehen wir eine Existenz. Wie beschreiben wir die Welt in der wir leben usw. An dieser Stelle wird innerhalb der Informatik eine Brücke zur Philosophie geschlagen. Wobei die Informatik eine klarere Sichtweise auf dieses Thema bietet.
Hier die Definition laut Gruber
An ontology is a formal specification of a shared conceptualization of a domain of interest
Die Ontologie ist eine formale Spezifikation von einer geteilten Konzeptualisierung einer konkreten Fachdomäne. Das führt genau zum Semantic Web und dem RDF. An dieser Stelle wird jetzt die Bedeutung eines Prädikats hinterfragt und welche Wertebereiche es umfassen kann sowohl auch wie das Prädikat mit anderen Prädikaten zusammenhängt. Grundsätzlich werden die gesamten Zusammenhänge innerhalb des Semantic Web hinterfragt. Was soll eine Ontologie leisten?
Ontologie - Anforderungen
1.In der Praxis sollen Klassen instanziiert, dass bedeutet es soll zu Konzepten und Begriffen die Möglichkeit geben zu sagen welche Individuen das erfüllen das und welche in eine bestimmte Klasse rein gehören .
2. Es soll eine Möglichkeit geben, Begriffshierarchien zu bilden (siehe Taxonomie)
3. Binäre Relationen zwischen Individuen sollen möglich sein (siehe RDFS Properties)
4. Relationaleeigenschaften sollen ermöglicht werden (siehe Domain und Range)
5. Es sollen konkretere Domänen ermöglicht werden. (siehe Datentypen)
6. Logische Ausdrucksmittel der Mengenlehre etc. sollen ein Bestandteil sein der angewendet werden kann.
7. Die Bedeutung eines Begriffes soll durch eine klare Semantik verstärkt werden.
Klassen Instanziierung in RDFS als einfaches Ontologie Beispiel
An diesen Beispiel wird die Instanzierungsbeziehung verdeutlicht.

Relation in RDFS
An dieser Stelle wird bereits die Domain und die Range definiert.

RDFS Auswertung
Die Frage lautet genügt RDFS, um als Ontologiesprache eingesetzt zu werden bzw. um die Semantik von bestimmten Konzepten im Web darzustellen? Mit dieser Frage hatte sich das W3C beschäftigt. Es gibt bestimmte Lücken die in RDFS nicht dargestellt werden können, die aber wiederum zu einer Ontologiesprache gehören.
RDFS Problembeispiele bei der Darstellung
1. Beispiel bei der Kardinalität. Jedes Projekt hat mindestens einen Mitarbeiter und höchstens 8.
2. Projekte sind immer interne oder externe Projekte und nichts anderes. Beim Web gillt allerdings immer die Open World Assumption
das bedeutet was nicht ausgedrückt wird bedeutet es grundsätzlich immer das es aber sein kann.
3. Einschränkungen auf Individuen z.B. Im Sekretariat von Frau Meier sitzen genau Frau Schulz und Herr Müller und kein anderer Mensch
4. Transitivität: Der Vorgesetzte meines Vorgesetzten ist auch mein Vorgesetzter.
Zusammenfassung
RDF ist gut genug für ganz einfache Ontologien aber bei komplexeren Modellierungen ist RDF ungeeignet und es muss auf eine
mächtigere Ontologiesprache wie OWL zurückgegriffen werden.
OWL

OWL ist eine prädikatenlogische Sprache basierend auf der first Order Logic. Unter OWL wird die Ballance gesucht zwischen der Ausdruckstärke und effizientem Schlussfolgern. Die Komplexität dieser Sprache werden in verschiedenen Teilsprachen ausgedrückt.
Bei OWL wie für RDFS gibt es die bekannten drei Bausteine. Die Klassen sind auch unter OWL Klassen und sind auch mit den RDFS Klassen vergleichbar. Ressourcen werden unter OWL Individuen genannt und die Properties werden durch Rollen beschrieben.
OWL Lite - die geringste Ausdrucksstärke die mit OWL erreicht wird.
OWL DL
OWL Full - die größte und komplexeste Ausdrucksstärke.
OWL Klassen
Dadurch wird das Tripel Professor rdf:type owl:Class beschrieben es existieren aber auch vordefinierte Klasen wie z.B.
owl:Thing innerhalb dieser Klasse ist alles vorhanden egal was definiert wird und owl:Nothing innerhalb dieser Klasse kann es keine Instanzen geben.
RDFS

OWL

OWL Individuen
Die Klassenzugehörigkeit wird über das Type-Prädikat definiert.
RDFS

gleichbedeutend mit

OWL abstrakte Rollen
Die abstrakten Rollen werden wie Klassen definiert. Das Prädikat bzw. die Rolle ist dem konkreten Beispiel die Zugehörigkeit.
OWL

Ein weiteres Beispiel mit Domain und Range bei einer abstrakten Rolle. Indem es zwischen das Tag definiert wird.

OWL konkreten Rollen
Hier werden die Individuen mit konkreten Datenwerten verbunden.
OWL
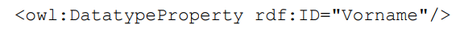
Hier das Beispiel mit Domain und Range unter der Verwendung von konkreten Rollen.
Die Rollen sind dabei die Datatypeproperties. An dieser Stellen können erneut XML Datentypen für die Definition verwendet werden.
Die OWL Ontologie selbst bietet nur Integer Datentypen an.

OWL Individuen und Rollen
Zeigt auf den ersten Blick deutliche objektorientierte Ansätze. Es wird eine bestimmte Ressource definiert. In diesem konkreten Fall die Prof. Ulrike Steffens dann wird das Klassentag um die Propertietags herum gewrappt. Innerhalb dieser Ressource verweist das Prädikat Zugehörigkeit und weist es z.B. auf die Fakultät TI zu. Die letzte Property ist eine Datatypeproperty wo der Vorname definiert wird. Rollen sind nicht funktional das bedeutet das die Rollen nicht auf andere Werte hinaus verweisen können.

OWL Klassenbeziehungen
Dieses Konzept wurde aus RDFS importiert. Die Funktionsweise ist die gleiche wie in RDFS über die Sub-Klassenbeziehung.
Dort können Beweise durch Inferenzen getroffen werden in diesen konkreten Fall ob der Professor eine Subklasse von einer Person ist.

OWL Zusammenfassung
Was ist der Mehrwert von OWL im Gegensatz zu RDFS?
1. Disjunktheit von Klassen kann dargestellt werden. Es kann dabei für eine bestimmte Klasse ausgedrückt werden das alle Instanzen die diese Klasse birgt auf keinen Fall in einer anderen Klasse wieder vorkommen sollen.
2. Äquivalenz von Klassen. Das ist dann Sinnvoll wenn Ontologien eingesetzt werden, die sich über mehrere Sprachen erstrecken.
3. Unterschiedliche Rolleneigenschaften können festgelegt werden. Rollen können z.B. Symetrisch sein. A -> B dann B -> A
4. Beziehung zwischen Individuen können festgelegt werden. Konkreter Fall wäre wenn zwei unterschiedliche Internetseite auf das selbe Individuum zeigen.
5. Abgeschlossene Klassen können direkt definiert werden.
6. Die Mengenlehre ist verfügbar wie Schnittmenge, Vereinigungen und Komplementen von Klassen sind möglich.
7. Rollen können eingeschränkt werden um z.B. Kardinalitäten zu ermöglichen.
Eigene Meinung zur Vorlesung
Die kleine Fingerübung zu RDF hatte mir gefallen, um etwas mehr in die Materie einzusteigen. Das gesamte Thema ist sehr, sehr syntaxlastig, wurde aber durch die zahlreichen Graphenbeispiele gut aufgelockert, dennoch ist der lange Atem notwendig um alle wichtigen Einzelheiten von RDF zu verstehen und diese nachvollziehen.